Category: Amazon Polly
Amazon Rekognition – 이미지 관리 및 Amazon Polly – 음성 표식 및 속삭임 생성 기능 업데이트
지난 re:Invent 2016 행사에서 개발자들이 손쉽게 스마트 애플리케이션을 개발할 수 있는 딥러닝 기반의 이미지 인식 서비스인 Amazon Rekognition과 Amazon Polly 및 Amazon Lex 등을 출시하였습니다. 이들 인공 지능 서비스에 최근 새로운 기능을 추가하였습니다. 이 글에서는 최근 업데이트 기능에 대해 간단하게 알아보겠습니다.
Amazon Rekognition에 이미지 관리 기능
사용자가 프로필 사진에 대해 올린 경우, 사진이 적합하지 않은 콘텐츠인 경우 이미지를 식별할 수 있습니다. 상세한 레이블을 통해 허용 이미지 종류를 결정하는 미세 필터를 조정할 수 있습니다.
본 기능을 활용하려면 DetectModerationLabels 함수를 호출하면, 아래와 같은 응답을 통해 활용 가능합니다.
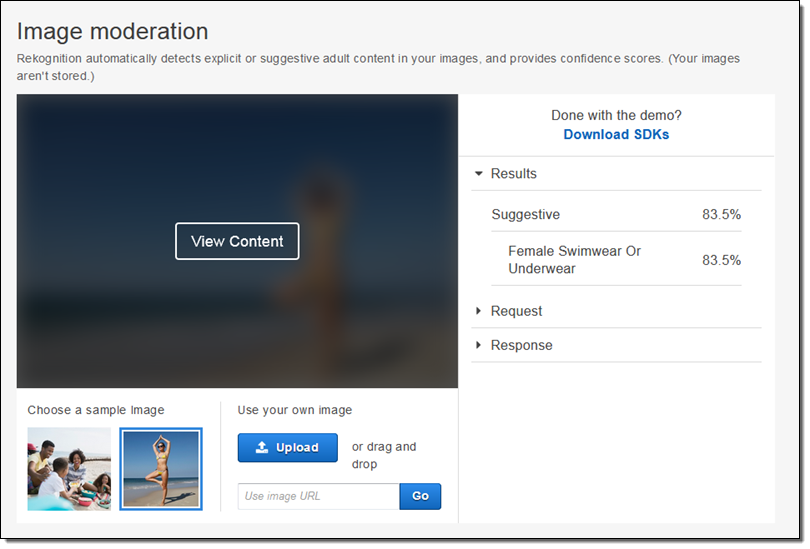
더 자세한 것은 Image Moderation 데모 기능을 통해 확인할 수 있습니다.
Amazon Polly 음성 표식 기능 및 속삭임 기능 출시
음성 표식(SppechMark) 기능은 개발자가 음성을 시각적 경험과 동기화 할 수 있습니다. 이 기능을 사용하면 음성을 얼굴 애니메이션과 동기화하거나 말한대로 단어의 강조 표시를 사용하여 립싱크와 같은 시나리오를 만들 수 있습니다. 음성 표식 메타 데이터는 합성된 음성을 설명하고 음성 오디오 스트림과 함께 사용함으로써 사운드, 단어, 문장 및 SSML 태그의 시작과 끝을 결정할 수 있습니다. 개발자는 립싱크 아바타를 만들고, 시각적으로 읽은 경험을 강조하고, Amazon Lumberyard와 같은 게임 엔진에 음성 기능을 통합하여 캐릭터에게 음성을 제공 할 수 있습니다.
네 가지 유형의 음성 표시가 있습니다.
- 문장 : 입력 텍스트에서 문장 요소를 지정합니다.
- 단어 : 입력 텍스트의 단어 요소를 나타냅니다.
- Viseme : 말한 소리에 해당하는 얼굴과 입의 위치를 보여줍니다.
- SSML (Speech Synthesis Markup Language) : SSML 입력 텍스트에서 <mark> 요소를 설명합니다.
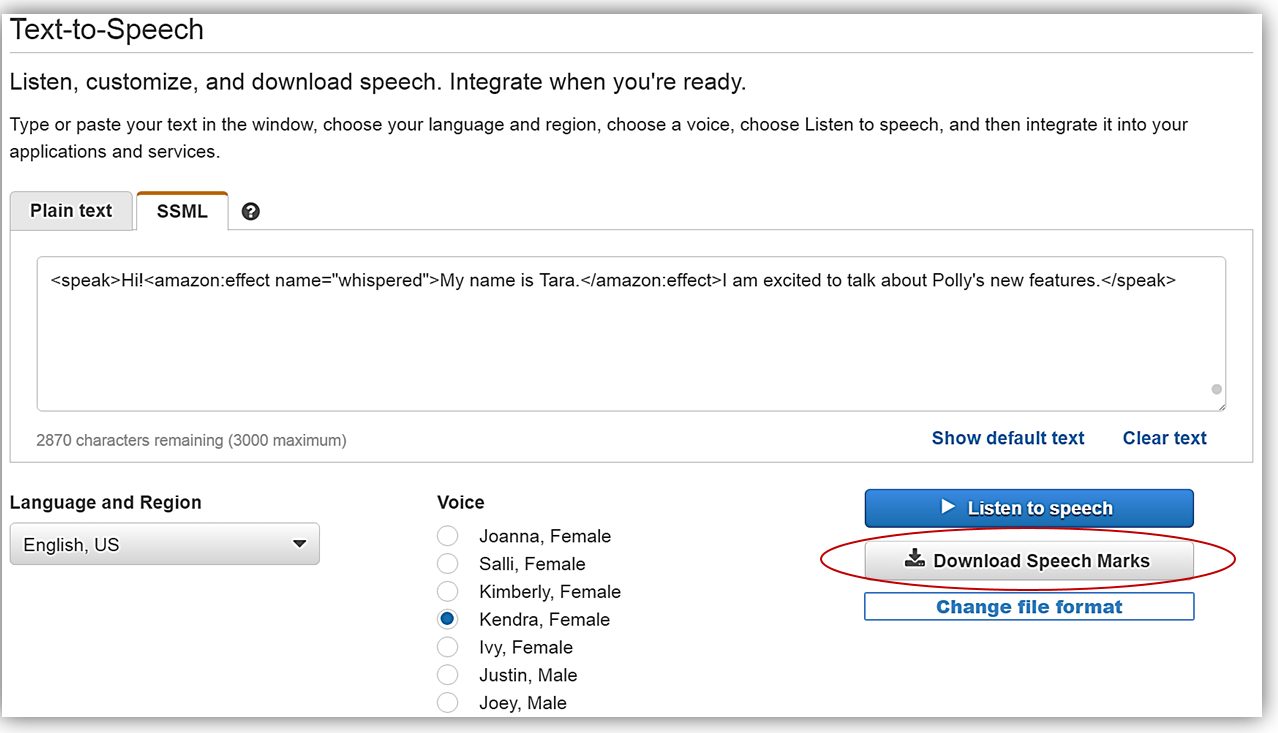
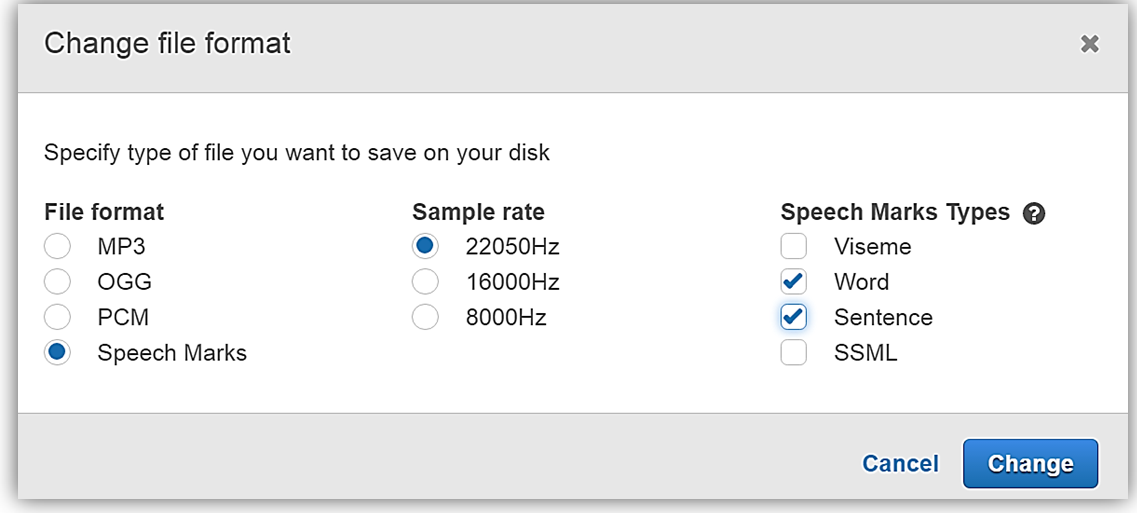
Amazon Polly에서 Change file format을 누른 후, File Format 옵션에서 Speech Marks를 선택합니다. Change 버튼을 눌러서 다운로드 포맷을 바꿀 수 있습니다.
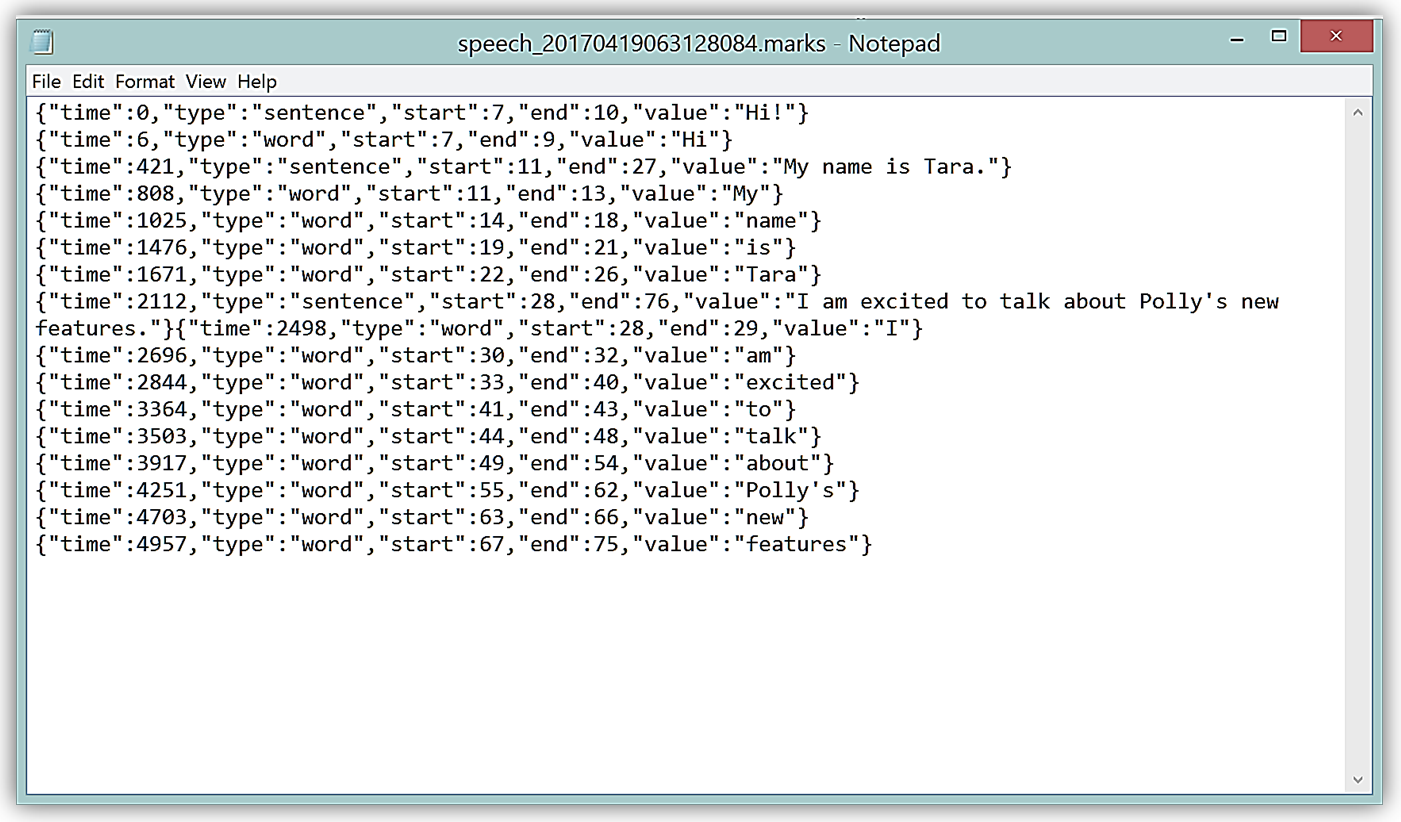
다운로드를 하면, 다음과 같이 음성 표식이 있는 텍스트 파일을 다운로드 할 수 있습니다.
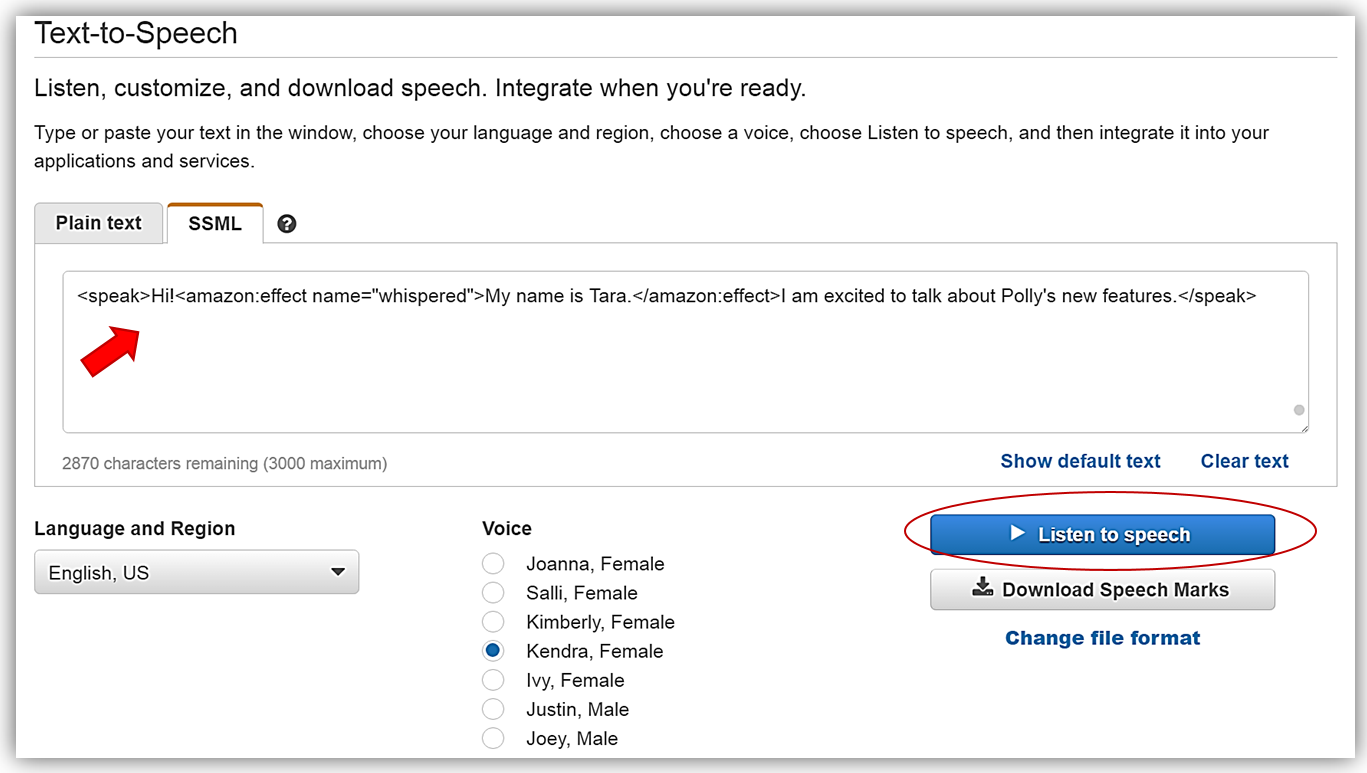
속삭임 기능은 개발자가 Text-to-Speech 출력을 수정할 수있는 표현형 음성 기능에서 피치, 템포 및 소리 크기에 대한 음성 효과입니다. 속삭이는 기능을 사용하면 개발자는 <amazon:effect name=”whispered”> SSML 요소를 사용하여 속삭이는 음성으로 말한 입력 텍스트의 단어를 가질 수 있습니다.
<speak>Hi!<amazon:effect name="whispered">My name is Tara.</amazon:effect>I am excited to talk about Polly's new features.</speak>
위의 마크업을 복사 한 후, Listen to speech 버튼을 누르면 “My name is Tara” 는 속삭임 소리로 들리게 됩니다.
본 기능 업데이트에 대한 자세한 소개는 아래를 참고하세요.
– Channy;
Amazon Polly – 클라우드 기반 24개 언어 47개 음성 합성 서비스
어린 시절 (TV를 많이 보던 때)로 돌아가면, 1960년대와 70년대 매우 유명한 로봇 소리가 다시 기억이 납니다. 특히, HAL-9000, B9 (Lost in Space), 오리지널 Star Trek Computer, 밋 Rosie (The Jetsons)과 같은 영화에서 익숙한 음성이 생각나실 것입니다. 그 때는 기계적으로 생성된 음성이 인간의 감정과 표현을 그대로 재현한다는 것은 불가능하다고 생각했습니다.
세월이 흘러 이제는 컴퓨터가 생성하는 음성을 사용하는 다양한 애플리케이션과 사용 사례가 있고, 흔히 TTS(Text-to-Speech)라고 알려진 음성 합성은 게임, 알림, 이러닝, 화상 통화 및 고객 센터 응대 등에서 많이 활용되고 있습니다. 이러한 애플리케이션 중 상당수는 연결성이 뛰어나고, 로컬 프로세싱 성능 및 스토리지가 최상의 수준인 모바일 환경에 매우 적합합니다.
Amazon Polly 서비스 소개
이러한 사용 사례를 지원하기 위해 오늘 Amazon Polly 서비스를 출시합니다. Polly는 여러분의 애플리케이션 및 도구에서 활용가능한 클라우드 기반 음성 합성 서비스입니다. 현재 47개의 남성 혹은 여성 목소리와 24개 언어를 지원하고, 추가적으로 더 다양한 언어 및 음성을 서비스할 계획입니다.
Polly는 다양한 음성 합성의 기술적 도전을 극복하고 있습니다. 예를 들어, “I live in Seattle”에서 live(리브)와 “Live from New York.”에서 Live(라이브)를 구별합니다. 같은 단어가 다른 맥락에서 사용될 때의 발음 방식에 대해 정보를 가지고 있습니다. “St.”의 경우도 맥락에 따라 “street” 또는 “saint.”로 발음됩니다. 또한, Polly는 단위, 약자, 화폐 단위, 날짜, 시간 등 언어별로 다른 부분에 대해 유연하게 처리합니다.
이를 위해 전문적인 모국어 구사자들과 함께 작업을 하고, 각 언어 구사자들에게 개별 언어 내 무수히 많은 대표적인 단어와 어구를 발음하도록 요청한 다음, 그 오디오를 diphone이라고하는 음원으로 분해합니다.
Polly는 일반 텍스트를 전달 받아, 문맥과 내용에 따라 가장 정확하고 자연스러운 음성을 오디오 파일로 전환하여 스트리밍으로 제공하게 됩니다. 좀 더 다양한 기능을 추가하고 싶다면, SSML (Speech Synthesis Markup Language) 정보를 제공할 수 있습니다. 예를 들어, 하나의 문장에 영어와 프랑스어 단어가 섞여 있다던지, 어구 강조를 한다던지 하는 부분에 대한 SSML 의미적 태깅을 통해 음성이 달리 변환됩니다.
본 블로그에 음성 파일을 임베딩할 수 없지만, Polly Console에 가셔서, 여러분이 원하는 텍스트를 직접 입력 한 후 Listen to speech를 눌러 들을 수 있습니다.
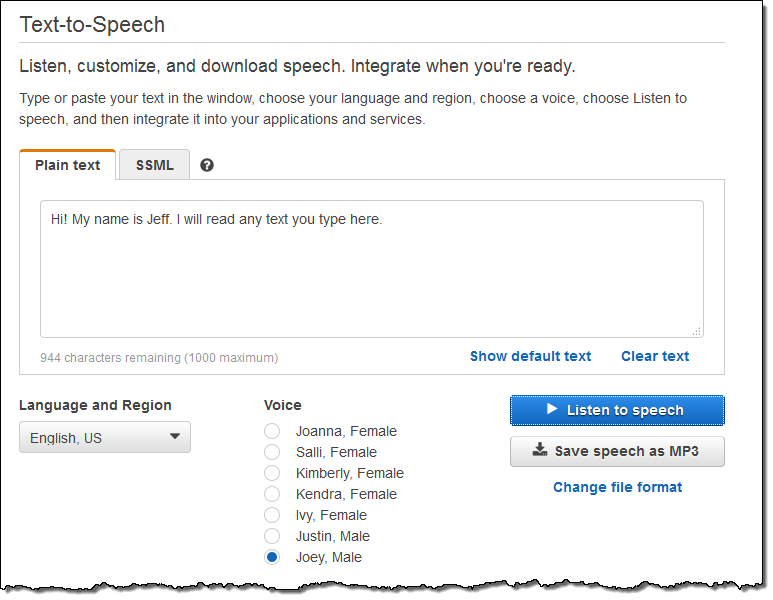 MP3 파일로 저장하여 애플리케이션에서 사용할 수 있습니다.
MP3 파일로 저장하여 애플리케이션에서 사용할 수 있습니다.
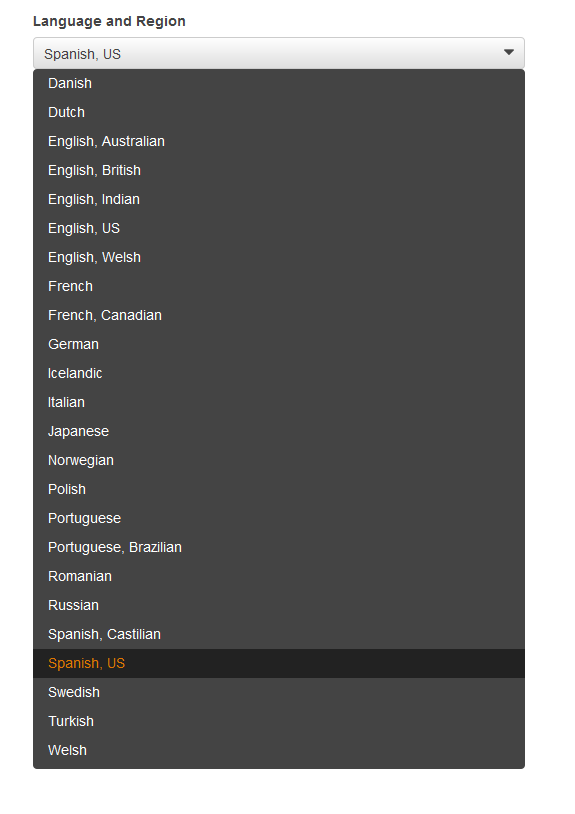
Language and Region 메뉴를 누르면, 지원 하는 언어 및 국가를 보실 수 있습니다.
API 및 기술적 세부 정보
Polly 콘솔 뿐만 아니라 다양한 방식으로 자유롭게 서비스를 이용하려면, 텍스트 및 SSML을 SynthesizeSpeech API로 호출 하면 됩니다. 결과를 사용자에게 스트리밍으로 전달하거나, MP3 혹은 OGG 파일로 생성해서 원할 때 제공할 수 있습니다. MP3 또는 Vorbis 포맷의 고품질 오디오 (최대 22 kHz 샘플링) 및 PCM 포맷의 전화 음성 (8 kHz)을 지원합니다.
AWS Command Line Interface (CLI) 를 사용할 수도 있습니다.
$ aws polly synthesize-speech \
--output-format mp3 --voice-id Joanna \
--text "Hello my name is Joanna." \
joanna.mp3Polly는 모든 전송 데이터를 SSL을 통해 암호화 합니다. 제공된 텍스트는 Polly의 성능을 유지하기 위해 6개월까지 암호화 된 상태로 저장됩니다.
정식 출시 및 가격
Amazon Polly는 월 5백만자 까지 무료로 제공됩니다. 그 이상의 경우, 한 자당 $0.000004 per 또는 제작된 오디오 분당 $0.004로 과금 됩니다. 본 블로그의 영문 포스트의 경우, 약 $0.018 이고, Adventures of Huckleberry Finn이라는 책 원문 전체는 약$2.4 정도 됩니다.
Polly는 US East (Northern Virginia), US West (Oregon), US East (Ohio), EU (Ireland) 리전에서 지금 바로 사용할 수 있습니다.
— Jeff;
이 글은 AWS re:Invent 2016 신규 출시 소식으로 Polly – Text to Speech in 47 Voices and 24 Languages의 한국어 번역입니다. re:Invent 출시 소식에 대한 자세한 정보는 12월 온라인 세미나를 참고하시기 바랍니다.