一拍字节(PiB,等于 1,125,899,906,842,624 字节)的数据堪称巨量,仅比人脑的估计记忆容量的一半略低。数据湖、高性能计算 (HPC) 和电子设计自动化 (EDA) 应用程序通常都以此规模运行,机器学习和媒体处理等更新的数据密集型应用程序也是如此。
Amazon FSx for Lustre
今天我们正是推出 Amazon FSx for Lustre 服务,旨在满足此类应用程序以及您无疑梦寐以求的其他应用程序的需求。Amazon FSx for Lustre 基于成熟的流行开源项目 Lustre,是一个高度并行的文件系统,可以在不到一毫秒的时间内访问 PB 级的文件系统。数以千计的同步客户端(EC2 实例和本地服务器)可能会驱动百万级的 IOPS(输入/输出操作/秒)并且美妙传输数百 GB 的数据。
您可以在几分钟内创建文件系统,挂载任意数量的客户端,然后立即开始访问它。这是一种完全托管的服务,因此无任何维护和管理需求。您可以创建独立的文件系统以用于瞬时用途,也可以将它们无缝联接到 S3 存储桶,然后像 Lustre 文件系统一样访问存储桶中的内容。每个文件系统都采用 NVMe SSD 存储,以 3.6TiB 为单位递增,按照每 1TiB 预置容量 10000 IOPS 的速度,实现 200 Mbps 的总吞吐能力。
Lustre 文件系统的创建
您可以通过 AWS 管理控制台、CLI 或调用 CreateFileSystem 函数的方式来创建 Lustre 文件系统。今天我将使用 CLI;我直接指定 Lustre 终端节点的子网以及期望的存储容量:
$ aws fsx create-file-system --file-system-type LUSTRE --storage-capacity 3600 --subnet-ids subnet-009a1149
----------------------------------------------------------------------------------------------
| CreateFileSystem |
+--------------------------------------------------------------------------------------------+
|| FileSystem ||
|+-----------------+------------------------------------------------------------------------+|
|| CreationTime | 1542666225.28 ||
|| DNSName | fs-00a2e062546ff4fce.fsx.us-east-1.amazonaws.com ||
|| FileSystemId | fs-00a2e062546ff4fce ||
|| FileSystemType | LUSTRE ||
|| Lifecycle | CREATING ||
|| OwnerId | 012345678912 ||
|| ResourceARN | arn:aws:fsx:us-east-1:012345678912:file-system/fs-00a2e062546ff4fce ||
|| StorageCapacity| 3600 ||
|| VpcId | vpc-e68d9c81 ||
|+-----------------+------------------------------------------------------------------------+|
||| LustreConfiguration |||
||+----------------------------------------------------------------+-----------------------+||
||| WeeklyMaintenanceStartTime | 5:09:00 |||
||+----------------------------------------------------------------+-----------------------+||
||| SubnetIds |||
||+----------------------------------------------------------------------------------------+||
||| subnet-009a1149 |||
||+----------------------------------------------------------------------------------------+||
这将会需要大约 5 分钟的时间,然后它的状态将变为 AVAILABLE:
$ aws fsx describe-file-systems --file-system-id fs-00a2e062546ff4fce | grep Lifecycle
|| Lifecycle | AVAILABLE ||
我的 EC2 实例已经拥有 Lustre 内核模块并且安装了 Lustre 客户端:
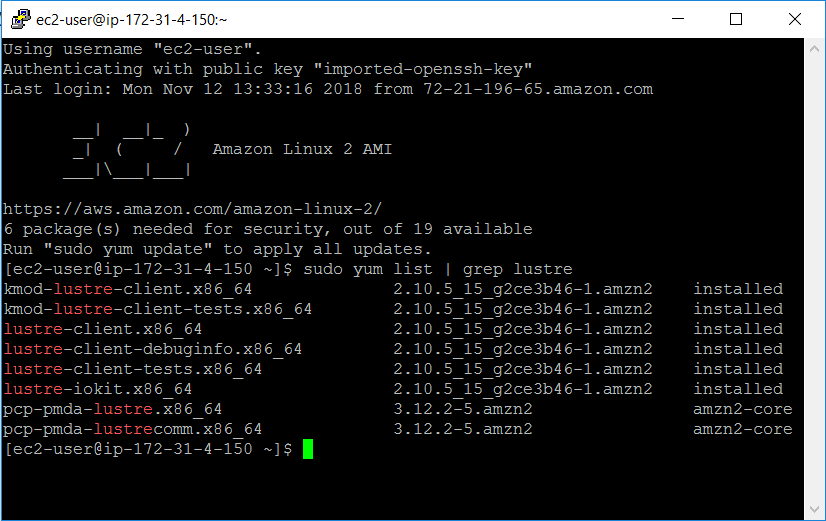
我创建了一个挂载点,然后挂载我的 Lustre 文件系统:
$ sudo mkdir /fsx
$ sudo mount -t lustre fs-00a2e062546ff4fce.fsx.us-east-1.amazonaws.com@tcp:/fsx /fsx
我的 3.4 TiB Lustre 文件系统也准备好可以使用:
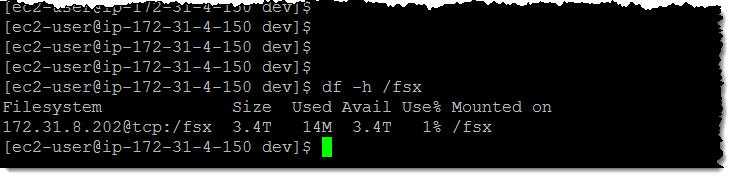
我可以创建一个位于 S3 存储桶(或 S3 存储桶的前缀部分)之前的文件系统。这样可以将我存储桶作为数据湖,使用基于文件的工具和应用程序进行处理。我在创建文件系统时直接包含了存储桶名称 ImportPath:
$ aws fsx create-file-system --file-system-type LUSTRE --storage-capacity 3600 \
--subnet-ids subnet-009a1149 --lustre-configuration ImportPath=s3://jbarr-src
我的存储桶包含大约 100 万个文件,因此创建过程花费了大约 30 分钟(团队告诉我每秒大约可创建 500 个文件)。这就是我的存储桶:
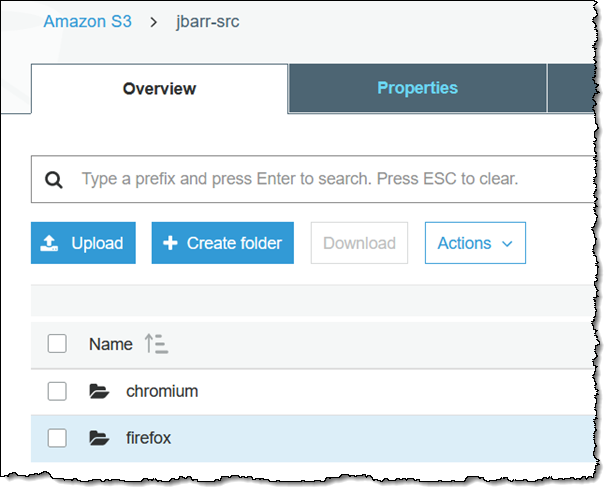
这是从我的 EC2 实例中看到的样子:
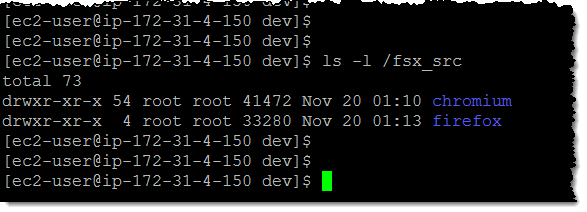
这时,Lustre 文件系统包含我的对象的所有元数据(名称、日期、大小等等),但没有实际的文件数据。此数据将根据需要从 S3 中复制。因此,此命令不会访问 S3:
而下面的这个命令将会访问,每次访问有小的延迟,因为将会根据需要将对象从 S3 复制到文件系统中:
$ find . -type f -exec grep -l -i main {} \;
如果我理解自己代码的访问模式,则可以使用 lfs 命令的 hsm_restore 选项来预加载代码。也许我计划分析所有 C 标头文件:
$ find . -type f -name '*.h' -print0 | \
xargs -0 -n 50 -P 8 sudo lfs hsm_restore
我对文件作出的所有更改将继续存在于文件系统中。我可以使用 lfs 命令的 hsm_archive 选项将更改后的文件导出回 S3 中:
$ sudo lfs hsm_archive README.md
$ sudo lfs hsm_action README.md
第一个命令启动了到处操作,第二个命令通过打印 NOOP 表示操作已经完成。更改后的文件将被写入同一个存储桶,并以文件系统的 ExportPath 为前缀:
我可以在命令行找到 ExportPath:
$ aws fsx describe-file-systems --file-system-id fs-086f5160a68bc158b | grep Path
|||| ExportPath | s3://jbarr-src/FSxLustre20181120T005845Z ||||
|||| ImportPath | s3://jbarr-src ||||
每个文件系统都向 CloudWatch 发布一组丰富的指标:
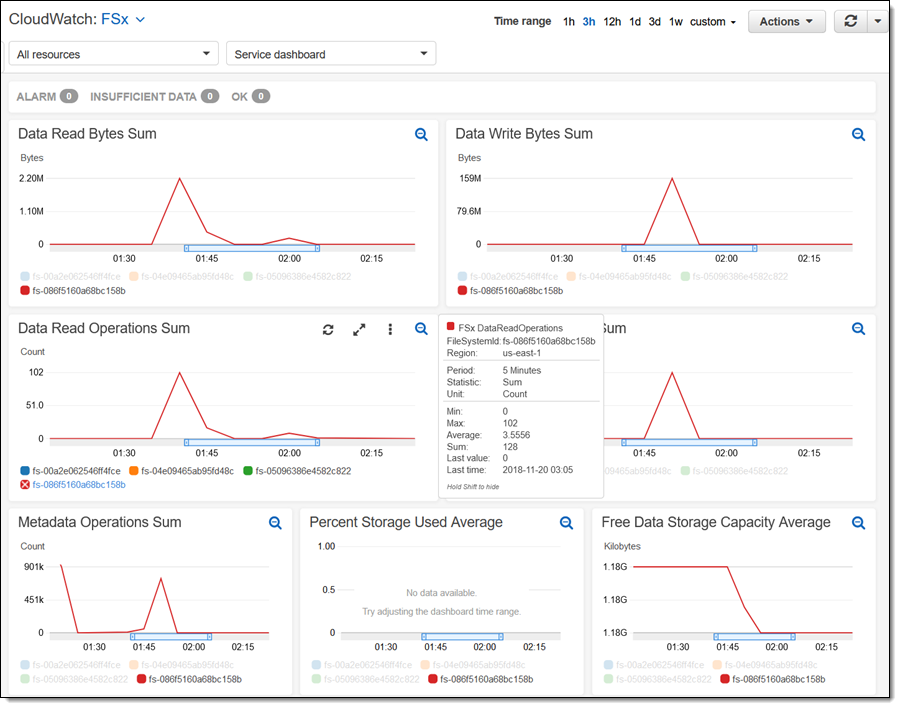
当然还有更多,这里就不一一详述了! 例如,我没有演示您可以使用 Amazon FSx for Lustre 实现的规模。我使用了一个客户端,当然也可以轻松使用上千个客户端。
注意事项
对于 Amazon FSx for Lustre 需要注意以下几点:
使用控制台 — 我使用 CLI 编写了此博文;当然也完全可以使用控制台。
区域 — 您可以在美国东部(弗吉尼亚北部)、美国西部(俄勒冈)、美国东部(俄亥俄)和欧洲(爱尔兰)等区域创建 Lustre 文件系统。
定价 — 定价基于您预置的存储量,在美国东部(弗吉尼亚北部)、美国西部(俄勒冈)和欧洲(爱尔兰)区域的价格为每月每 GiB 0.14 USD 起。
访问 — 您可以从 EC2 实例访问您的文件系统。您还可以使用 AWS Direct Connect 将现有的数据中心或并置中心连接到 AWS,然后从那里访问您的文件系统。
安全性 — 每个文件系统的访问权限均通过安全组来控制,利用 IAM 策略实现精细的访问控制。静态数据使用 256 位块加密算法加密,密钥由 Amazon FSx for Lustre 管理。
现已推出
Amazon FSx for Lustre 现已推出,您可以立即开始使用!
– Jeff;