AWS News Blog
Amazon DynamoDB – Internet-Scale Data Storage the NoSQL Way

|
We want to make it very easy for you to be able to store any amount of semistructured data and to be able to read, write, and modify it quickly, efficiently, and with predictable performance. We don’t want you to have to worry about servers, disks, replication, failover, monitoring, software installation, configuration, or updating, hardware upgrades, network bandwidth, free space, sharding, rearchitecting, or a host of other things that will jump up and bite you at the worst possible time.
We want you to think big, to dream big dreams, and to envision (and then build) data-intensive applications that can scale from zero users up to tens or hundreds of millions of users before you know it. We want you to succeed, and we don’t want your database to get in the way. Focus on your app and on building a user base, and leave the driving to us.
Sound good?
Hello, DynamoDB
Today we are introducing Amazon DynamoDB, our Internet-scale NoSQL database service. Built from the ground up to be efficient, scalable, and highly reliable, DynamoDB will let you store as much data as you want and to access it as often as you’d like, with predictable performance brought on by the use of Solid State Disk, better known as SSD.
DynamoDB works on the basis of provisioned throughput. When you create a DynamoDB table, you simply tell us how much read and write throughput you need. Behind the scenes we’ll set things up so that we can meet your needs, while maintaining latency that’s in the single-digit milliseconds. Later, if your needs change, you can simply turn the provisioned throughput dial up (or down) and we’ll adjust accordingly. You can do this online, with no downtime and with no impact on the overall throughput. In other words, you can scale up even when your database is handling requests.
We’ve made DynamoDB ridiculously easy to use. Newly created tables will usually be ready to use within a minute or two. Once the table is ready, you simply start storing data (as much as you want) into it, paying only for the storage that you use (there’s no need to pre-provision storage).Again, behind the scenes, we’ll take care of provisioning adequate storage for you.
Each table must have a primary index. In this release, you can choose between two types of primary keys: Simple Hash Keys and Composite Hash Key with Range Keys.
- Simple Hash Keys give DynamoDB the Distributed Hash Table abstraction and are used to index on a unique key. The key is hashed over multiple processing and storage partitions to optimally distribute the workload.
- Composite Hash Keys with Range Keys give you the ability to create a primary key that is composed of two attributes — a hash attribute and a range attribute. When you query against this type of key, the hash attribute must be uniquely matched but a range (low to high) can be specified for the range attribute. You can use this to run queries such as “all orders from Jeff in the last 24 hours.”
Each item in a DynamoDB table consists of a set of key/value pairs. Each value can be a string, a number, a string set, or a number set. When you choose to retrieve (get) an item, you can choose between a strongly consistent read and an eventually consistent read based on your needs. The eventually consistent reads consume half as many resources, so there’s a throughput consideration to think about.
Sounds great, you say, but what about reliability and data durability? Don’t worry, we’ve got that covered too! When you create a DynamoDB table in a particular region, we’ll synchronously replicate your data across servers in multiple zones. You’ll never know about (or be affected by) hardware or facility failures. If something breaks, we’ll get the data from another server.
I can’t stress the operational performance of DynamoDB enough. You can start small (say 5 reads per second) and scale up to 50, 500, 5000, or even 50,000 reads per second. Again, online, and with no changes to your code. And (of course) you can do the same for writes. DynamoDB will grow with you, and it is not going to get between you and success.
As part of the AWS Free Usage Tier, you get 100 MB of free storage, 5 writes per second, and 10 strongly consistent reads per second (or 20 eventually consistent reads per second). Beyond that, pricing is based on how much throughput you provision and how much data you store. As is always the case with AWS, there’s no charge for bandwidth between an EC2 instance and a DynamoDB table in the same Region.
You can create up to 256 tables, each provisioned for 10,000 reads and 10,000 writes per seconds. I cannot emphasize the next point strongly enough: We are ready, willing, and able to increase any of these values. Our early customers have, in several cases, already exceeded the default limits by an order of magnitude!
DynamoDB from the AWS Management Console
The AWS Management Console has a new DynamoDB tab. You can create a new table, provision the throughput, set up the index, and configure CloudWatch alarms with a few clicks:
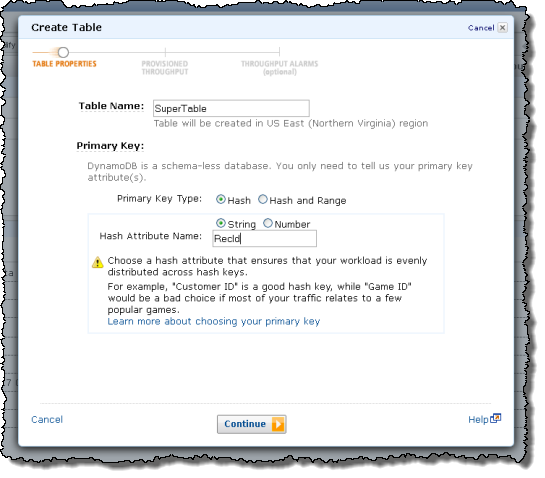
You can enter your throughput requirements manually:

Or you can use the calculator embedded in the dialog:

You can easily set CloudWatch alarms that will fire when you are consuming more than a specified percentage of the throughput that you have provisioned for the table:
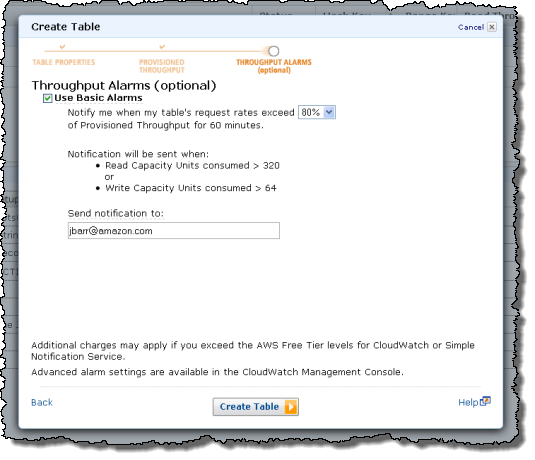
You can use the CloudWatch metrics to see when it is time to add additional read or write throughput:

You can easily increase or decrease the provisioned throughput:

Programming With DynamoDB
The AWS SDKs have been updated and now include complete support for DynamoDB. Here are some examples that I put together using the AWS SDK for PHP.
The first step is to include the SDK and create a reference object:
$DDB = new AmazonDynamoDB ( array ( ‘credentials’ => ‘production’ ) ) ;
Creating a table requires three arguments: a table name, a key specification, and a throughput specification:
$Schema = array ( ‘HashKeyElement’ =>
array ( ‘AttributeName’ => ‘RecordId’ ,
‘AttributeType’ => AmazonDynamoDB :: TYPE_STRING ) ) ; $Throughput = array ( ‘ReadsPerSecond’ => 5 , ‘WritesPerSecond’ => 5 ) ;
$Res = $DDB->create_table(array(‘TableName’ => ‘Sample’,
‘KeySchema’ => $Schema,
‘ProvisionedThroughput’ => $Throughput));
After create_table returns, the table’s status will be CREATING. It will transition to ACTIVE when the table is provisioned and ready to accept data. You can use the describe_table function to get the status and other information about the table:
print_r ( $Res -> body -> Table ) ;
Here’s the result as a PHP object:
(
[CreationDateTime ] => 1324673829.32
[ItemCount ] => 0
[KeySchema ] => CFSimpleXML Object
(
[HashKeyElement ] => CFSimpleXML Object
(
[AttributeName ] => RecordId
[AttributeType ] => S
) )
[ProvisionedThroughput] => CFSimpleXML Object
(
[ReadsPerSecond] => 5
[WritesPerSecond] => 5
)
[TableName] => Sample
[TableSizeBytes] => 0
[TableStatus] => ACTIVE
)
It is really easy to insert new items. You need to specify the data type of each item; here’s how you do that (the other data type constants are TYPE_ARRAY_OF_STRINGS and TYPE_ARRAY_OF_NUMBERS):
{
print ( $i ) ;
$Item = array ( ‘RecordId’ => array (AmazonDynamoDB :: TYPE_STRING => (string ) $i ) ,
‘Square’ => array (AmazonDynamoDB :: TYPE_NUMBER => (string ) ( $i * $i ) ) ) ; $Res = $DDB -> put_item ( array ( ‘TableName’ => ‘Sample’ , ‘Item’ => $Item ) ) ;
}
Retrieval by the RecordId key is equally easy:
{
$Key = array ( ‘HashKeyElement’ => array (AmazonDynamoDB :: TYPE_STRING => (string ) $i ) ) ; $Item = $DDB -> get_item ( array ( ‘TableName’ => TABLE ,
‘Key’ => $Key ) ) ;
print_r($Item->body->Item);
}
Each returned item looks like this as a PHP object:
(
[RecordId ] => CFSimpleXML Object
(
[S ] => 44
) [Square ] => CFSimpleXML Object
(
[N ] => 1936
)
)
The DynamoDB API also includes query and scan functions. The query function queries primary key attribute values and supports the use of comparison operators. The scan function scans the entire table with optional filtering of the results of the scan. Queries are generally more efficient than scans.
You can also update items, retrieve multiple items, delete items, or delete multiple items. DynamoDB includes conditional updates (to ensure that some other write hasn’t occurred within a read/modify/write operation as well as atomic increment and decrement operations). Read more in the Amazon DynamoDB Developer Guide.
And there you have it, our first big release of 2012. I would enjoy hearing more about how you plan to put DynamoDB to use in your application. Please feel free to leave a comment on the blog.
— Jeff;