AWS News Blog
Amazon EMR Release 4.1.0 – Spark 1.5.0, Hue 3.7.1, HDFS Encryption, Presto, Oozie, Zeppelin, Improved Resizing
My colleagues Jon Fritz and Abhishek Sinha are both Senior Product Managers on the EMR team. They wrote the guest post below to introduce you to the newest release of EMR and to tell you about new EMR cluster resizing functionality.
— Jeff;
Amazon EMR is a managed service that simplifies running and managing distributed data processing frameworks, such as Apache Hadoop and Apache Spark.
Today we are announcing Amazon EMR release 4.1.0, which includes support for Spark 1.5.0, Hue 3.7.1 and HDFS transparent encryption with Hadoop KMS. We are also introducing an intelligent resize feature that allows you to reduce the number of nodes in your cluster with minimal impact to running jobs. Finally, we are also announcing the availability of Presto 0.119, Zeppelin 0.6 (Snapshot) and Oozie 4.0.1 as Sandbox Applications. The EMR Sandbox gives you early access to applications which are still in development for a full General Availability (GA) release.
EMR release 4.1.0 is our first follow-up release to 4.0.0, which brought many new platform improvements around configuration of applications, a new packaging system, standard ports and paths for Hadoop ecosystem applications, and a Quick Create option for clusters in the AWS Management Console.
New Applications and Components in the 4.x Release Series
Amazon EMR provides an easy way to install and configure distributed big data applications in the Hadoop and Spark ecosystems on your cluster when creating clusters from the EMR console, AWS CLI, or using a SDK with the EMR API. In release 4.1.0, we have added support for several new applications:
- Spark 1.5.0 – We included Spark 1.4.1 on EMR release 4.0.0, and we have upgraded the version of Spark to 1.5.0 in this EMR release. Spark 1.5.0 includes a variety of new features and bug fixes, including additional functions for Spark SQL/Dataframes, new algorithms in MLlib, improvements in the Python API for Spark Streaming, support for Parquet 1.7, and preferred locations for dynamically allocated executors. To learn more about Spark in Amazon EMR, click here.
- HUE 3.7.1 – Hadoop User Experience (HUE) is an open source user interface which allows users to more easily develop and run queries and workflows for Hadoop ecosystem applications, view tables in the Hive Metastore, and browse files in Amazon S3 and on-cluster HDFS. Multiple users can login to HUE on an Amazon EMR cluster to query data in Amazon S3 or HDFS using Apache Hive and Pig, create workflows using Oozie, develop and save queries for later use, and visualize query results in the UI. For more information about how to connect to the HUE UI on your cluster, click here.


- Hadoop KMS for HDFS Transparent Encryption – The Hadoop Key Management Server (KMS) can supply keys for HDFS Transparent Encryption, and it is installed on the master node of your EMR cluster with HDFS. You can also use a key vendor external to your EMR cluster which utilizes the Hadoop KeyProvider API. Encryption in HDFS is transparent to applications reading from and writing to HDFS, and data is encrypted in in-transit in HDFS because encryption and decryption activities are carried out in the client. Amazon EMR has also included an easy configuration option to programmatically create encrypted HDFS directories when launching clusters. To learn more about using Hadoop KMS with HDFS Transparent Encryption, click here.
Introducing the EMR Sandbox
With the EMR Sandbox, you now have early access to new software for your EMR cluster while those applications are still in development for a full General Availability (GA) release. Previously, bootstrap actions were the only mechanism to install applications not fully supported on EMR. However, you would need to specify a bootstrap action script, the installation was not tightly coupled to an EMR release, and configuration settings were harder to maintain. Instead, applications in the EMR Sandbox are certified to install correctly, configured using a configuration object, and specified directly from the EMR console, CLI, or EMR API using the application name (ApplicationName-Sandbox). Release 4.1.0 has three EMR Sandbox applications:
- Presto 0.119 – Presto is an open-source, distributed SQL query engine designed to query large data sets in one or more heterogeneous data sources, including Amazon S3. Presto is optimized for ad-hoc analysis at interactive speed and supports standard ANSI SQL, including complex queries, aggregations, joins, and window functions. Presto does not use Hadoop MapReduce; instead, it uses a query execution mechanism that processes data in memory and pipelines it across the network between stages. You can interact with Presto using the on-cluster Presto CLI or connect with a supported UI like Airpal, a web-based query execution tool which was open sourced by Airbnb. Airpal has several interesting features such as syntax highlighting, results exported to a CSV for download, query history, saved queries, table finder to search for appropriate tables, and a table explorer to visualize schema of a table and sample the first 1000 rows. To learn more about using Airpal with Presto on Amazon EMR, read the new post, Analyze Data with Presto and Airpal on Amazon EMR on the AWS Big Data Blog. To learn more about Presto on EMR, click here.
- Zeppelin 0.6 (Snapshot) – Zeppelin is an open source GUI which creates interactive and collaborative notebooks for data exploration using Spark. You can use Scala, Python, SQL (using Spark SQL), or HiveQL to manipulate data and quickly visualize results. Zeppelin notebooks can be shared among several users, and visualizations can be published to external dashboards. When executing code or queries in a notebook, you can enable dynamic allocation of Spark executors to programmatically assign resources or change Spark configuration settings (and restart the interpreter) in the Interpreter menu.
- Oozie 4.0.1 – Oozie is a workflow scheduler for Hadoop, where you can create Directed Acyclic Graphs (DAGs) of actions. Also, you can easily trigger your Hadoop workflows by actions or time.
Example Customer Use Cases for Presto on Amazon EMR
Even before Presto was supported as a Sandbox Application, many AWS customers have been using Presto on Amazon EMR, especially for interactive ad hoc queries on large scale data sets in Amazon S3. Here are a few examples:
- Cogo Labs, a startup incubator, operates a platform for marketing analytics and business intelligence. Presto running on Amazon EMR allows any of their 100+ developers and analysts to run SQL queries on over 500 TB of data stored in Amazon S3 for data-exploration, ad-hoc analysis, and reporting.
- Netflix has chosen Presto as their interactive, ANSI-SQL compliant query engine for big data, as Presto scales well, is open source, and integrates with the Hive Metastore and Amazon S3 (the backbone of Netflix’s Big Data Warehouse environment.) Netflix runs Presto on persistent EMR clusters to quickly and flexibly query across their ~25PB S3 data store. Netflix is an active contributor to Presto, and Amazon EMR provides Netflix with the flexibility to run their own build of Presto on Amazon EMR clusters. On average, Netflix runs ~3500 queries per day on their Presto clusters. Learn more about Netflix’s Presto deployment.
- Jampp is a mobile application marketing platform, and they use advertising retargeting techniques to drive engaged users to new applications. Jampp currently uses Presto on EMR to process 40 TB of data each day.
- Kanmu is Japanese startup in the financial services industry and provides offers based on consumers’ credit card usage. Kanmu migrated from Hive to using Presto on Amazon EMR because of Presto’s ability to run exploratory and iterative analytics at interactive speeds, good performance with Amazon S3, and scalability to query large data sets.
- OpenSpan provides automation and intelligence solutions that help bridge people, processes and technology to gain insight into employee productivity, simplify transactions, and engage employees and customers. OpenSpan migrated from HBase to Presto on Amazon EMR with Amazon S3 as a data layer. OpenSpan chose Presto because of its ANSI SQL interface and ability to query data in real-time directly from Amazon S3, which allows them to quickly explore vast amounts of data and rapidly iterate on upcoming data products.
Intelligent Resize Feature Set
In release 4.1.0, we have added an Intelligent Resize feature set so you can now shrink your EMR cluster with minimal impact to running jobs. Additionally, when adding instances to your cluster, EMR can now start utilizing provisioned capacity as soon it becomes available. Previously, EMR would need the entire requested capacity to become available before allowing YARN to send tasks to those nodes. Also, you can now issue a resize request to EMR while a current resize request is being executed (to change the target size of your cluster), or stop a resize operation.
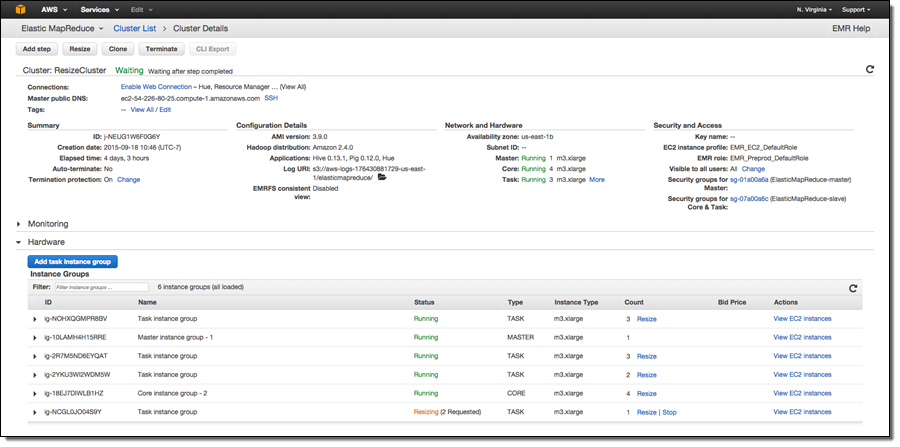
When decreasing the size of your cluster, EMR will programmatically select instances which are not running tasks, or if all instances in the cluster are being utilized, EMR will wait for tasks to complete on a given instance before removing it from the cluster. The default wait time is 1 hour, and this value can be changed. You can also specify a timeout value in seconds by changing the yarn.resourcemanager.decommissioning parameter in /home/hadoop/conf/yarn-site.xml or /etc/hadoop/conf/yarn-site.xml file. EMR will dynamically update the new setting and a resource manager restart is not required. You can set this to arbitrarily large number to ensure that no tasks are killed while shrinking the cluster.

Additionally, Amazon EMR now has support for removing instances in the core group, which store data as a part of HDFS along with running YARN components. When shrinking the number of instances in a cluster’s core group, EMR will gracefully decommission HDFS daemons on the instances. During the decommissioning process, HDFS replicates the blocks on that instance to other active instances to reach the desired replication factor in the cluster (EMR sets the default replication factor to 1 for 1-3 core nodes, the value to 2 for 4-9 core nodes, and the value to 3 for 10+ core nodes). To avoid data loss, EMR will not allow shrinking your core group below the storage required by HDFS to store data on the cluster, and will ensure that the cluster has enough free capacity to successfully replicate blocks from the decommissioned instance to the remaining instances. If the requested instance count is too low to fit existing HDFS data, only a partial number of instances will be decommissioned.
We recommend minimizing HDFS heavy writes before removing nodes from your core group. HDFS replication can slow down due to under-construction blocks and inconsistent replica blocks, which will decrease the performance of the overall resize operation. To learn more about resizing your EMR clusters, click here.

Launch an Amazon EMR Cluster With 4.1.0 Today
To create an EMR cluster with 4.1.0, select release 4.1.0 on the Create Cluster page in the AWS Management Console, or use the release label “emr-4.1.0” when creating your cluster from the AWS CLI or using a SDK with the EMR API.
— Jon Fritz and Abhishek Sinha