AWS Compute Blog
Optimizing network footprint in serverless applications
This post is authored by Anton Aleksandrov, Principal Solution Architect, AWS Serverless and Daniel Abib, Senior Specialist Solutions Architect, AWS
Serverless application developers may commonly encounter scenarios where they need to transport large payloads, especially when building modern cloud applications that need rich data. Examples include analytics services with detailed reports, e-commerce platforms with extensive product catalogs, healthcare applications transmitting patient records, or financial services aggregating transactional data.
Many serverless services have a well-defined maximum payload size. For example, AWS Lambda maximum request/response payload size is 6 MB, and Amazon Simple Queue Service (Amazon SQS) and Amazon EventBridge maximum message size is 256 KB. In this post, you will learn how to use data compression techniques to reduce your network footprint and transport larger payloads under existing constraints.
Overview
Cloud applications evolve continuously and need to be adjusted frequently for new requirements, such as new business features or new Service Level Objectives (SLO) for higher throughput and lower latency. As new use cases and data patterns are added, it is common to see request and response payload sizes increase. At some point, you might hit the maximum service payload size limits, such as 6 MB for synchronous Lambda function invokes, 10 MB for Amazon API Gateway, and 256 KB for Amazon SQS, EventBridge, and asynchronous Lambda invokes.
There are several techniques you can apply when dealing with large payloads. If your payloads are tens of MBs or more, or you need to transport large binary objects with API Gateway, you can store the payload on Amazon Simple Storage Service (Amazon S3) and use pre-signed URLs for clients to directly upload and download from S3.

Figure 1. A sample of architecture for handling large payloads
Lambda function URLs response streaming supports up to 20 MB responses. For handling large messages with services such as SQS or EventBridge, you can store the message in S3 and pass a reference. The downstream consumer will use the reference to download the message directly from S3. One common characteristic of these techniques is that they introduce architectural complexity and may necessitate modifications to your existing solution architecture and data flow patterns.
Furthermore, as your payloads grow in size, you will see increased data transfer costs, especially if your solution is transporting data through Amazon Virtual Private Cloud (VPC) NAT Gateways, VPC endpoints, or sending data across AWS Regions. For example, it is common for VPC-based solutions to have Lambda functions in their architecture. A container running on Amazon Elastic Kubernetes Service (Amazon EKS) might need to invoke a Lambda function, or a VPC-attached Lambda function might need to reach out to the public internet.
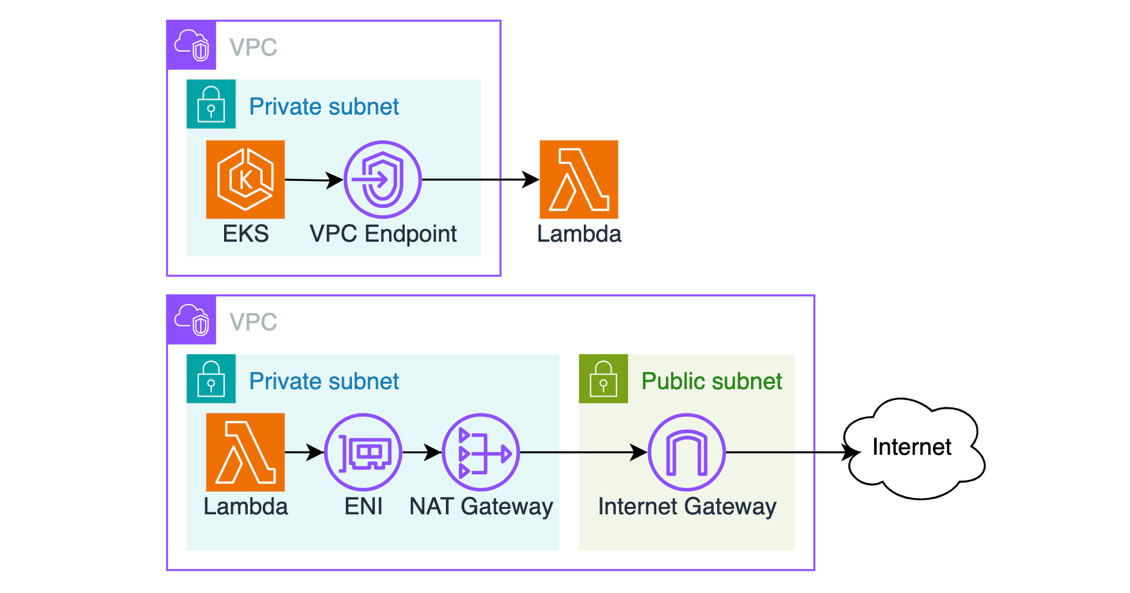
Figure 2. Examples of using virtual network appliances with serverless applications
Both NAT Gateway and VPC Endpoint are billed per GB of data processed, which makes data compression a valuable optimization technique. Go to NAT Gateway pricing and VPC Endpoint pricing for details.
The following sections explore data compression techniques and demonstrate how to apply them in your serverless applications. You can learn how to send larger payloads within the existing payload size boundaries and reduce your network footprint without significant architectural changes. This post discusses compression techniques in the context of Lambda and API Gateway, but the same principles can be applied to other services, such as SQS, EventBridge, and AWS AppSync. Understanding compression concepts better equips you to optimize your application’s data-handling capabilities.
What is data compression?
Compression is a widely used approach to reduce data size in order to improve cost-effectiveness and performance for data storage and transmission. Many tools and frameworks incorporate data compression techniques, such as gzip or zstd. It is thoroughly documented in the official IANA specification and IETF RFC 9110. Browsers such as Chrome and Firefox, HTTP toolkits such as curl and Postman, and runtimes such as Node.js and Python natively handle compression, often without user involvement.
Consider HTTP protocol. When a client wants to send a compressed payload, it specifies it in the Content-Type header. To receive a compressed response, the client specifies supported compression methods in the Accept-Encoding request header.

Figure 3. Accept-Encoding request header specifying supported compression methods
The server compresses the response payload using one of the supported methods and uses the Content-Encoding response header to indicate the method to the client.

Figure 4. Content-Encoding response header specifying compression method
This mechanism can accelerate client-server communications by reducing the number of bytes transmitted over the network. Compression efficiency depends on the data type. Text-based formats like JSON, XML, HTML, and YAML compress well, while binary data such as PDF and JPEG generally compress less effectively.
Data compression with API Gateway
API Gateway provides built-in compression support. Use the minimumCompressionSize configuration to set the smallest payload size to compress automatically. The value can be between 0 bytes to 10 MB. Compressing very small payloads might actually increase the final payload size, and you should always test with your real payload patterns to determine the optimal threshold.

Figure 5. Handling data compression in API Gateway
API Gateway enables clients to interact with your API using compressed payloads through supported content encodings. The compression mechanism works bi-directionally. For JSON payloads, API Gateway seamlessly handles compression and decompression, maintaining compatibility with mapping templates. It decompresses incoming payloads before applying request mapping templates and compresses outgoing responses after applying response mapping templates. This automated compression optimizes data transfer:
- When sending compressed data, clients supply the appropriate Content-Encoding header. API Gateway handles the decompression and applies configured mapping templates before forwarding the request to the integration.
- When API Gateway receives an integration response and compression is enabled, it compresses the response payload and returns it to the client, provided that the client has included a matching Accept-Encoding header.
A sample test using the compression technique with API Gateway and JSON payload yielded the following results.
- Compression disabled. Response size = 1 MB, response latency = 660 ms
- Compression enabled. Response size = 220 KB, response latency = 550 ms
Compressing data resulted in 78% network footprint reduction and improved latency by 110 ms.
This configuration-based technique uses the API Gateway native compression. However, payloads are decompressed before being delivered to downstream integrations, thus they still remain subject to Lambda’s 6 MB max payload size. To address this, you can configure binaryMediaTypes in the API Gateway to pass compressed payloads to Lambda directly, enabling the function to handle decompression.

Figure 6. CDK code to configure API Gateway for data compression and binary data passthrough
Handling compressed data in Lambda functions
The Lambda Invoke API supports payloads in plain-text formats, such as JSON. The maximum payload size is 6 MB for synchronous invocations and 256 KB for asynchronous. Although the Invoke API supports uncompressed text-based payloads, you can introduce data compression in your function code and use API Gateway or Function URLs to facilitate content conversion, as illustrated in the following figure.

Figure 7. Transporting compressed payloads in a serverless applications
Handling data compression in your Lambda function code can be done through libraries commonly embedded in the runtime. The following code snippet shows the compressing response payload using Node.js. Similar techniques can be applied to other runtimes.

Figure 8. Sample code implementing response payload compression in a Lambda function
- Line 1: Import gzip functionality from the zlib module.
- Lines 11: Compress and Base64-encode data. Gzip compression, similar to many other compression methods, produces a binary stream. Base64 encoding converts it to the text-based format expected by the Lambda service
- Lines 13-21: Response object is created with isBase64Encoded=true and response headers telling the client that the response is a gzip-encoded JSON object.
The following screenshot shows the result: 20 MB uncompressed JSON returned from a Lambda function as a 2.5 MB compressed response body. Network footprint reduced by over 80%.

Figure 9. A screenshot from Postman showing the original and compressed payload size
Using this technique, you can reduce your network footprint and transport payload sizes several times higher than the Lambda maximum payload size.
Using Function URLs with compressed payloads
Transporting compressed payloads through Lambda Function URLs doesn’t necessitate any extra configuration. For handler responses, your code needs to compress and Base64-encode the data as shown in the preceding figure. For invocation requests, the Function URL endpoint recognizes the incoming compressed payload as binary and passes it to your handler as a Base64 encoded string in the event body.

Figure 10. Sample code implementing request payload decompression in a Lambda function
Trade-offs and testing results
Compressing data in function code is a CPU-intensive activity, potentially increasing invocation duration and, as a result, function cost. This, however, can be balanced by the benefits of data compression. As you’ve seen in previous sections, while compressing data adds compute latency, transporting smaller payloads over the network reduces network latency. The following section summarizes a series of tests performed to estimate the impact of data compression on Lambda function invocation duration, Lambda function invocation cost, and data transfer savings with both NAT Gateway and VPC Endpoint. The tests were performed with several assumptions and randomly generated JSON data. You can see full testing results in the sample GitHub.com repo.
Test results demonstrated that the impact on function latency and cost primarily depends on two key factors: payload size and allocated memory (which determines vCPU capacity). Using a Node.js runtime with ARM architecture as an example, compressing a 1 MB JSON object in a function with 1 GB of allocated memory resulted in 124 ms of added processing time on average. For 10 million invocations, this extra processing time adds approximately $16. At the same time, the compression yielded a 70% reduction in payload size. With the same number of invocations, this translates to approximately $300 in savings when using NAT Gateway and $70 in savings when using VPC Endpoints (depending on the number of Availability Zones (AZs)).
AWS Service pricing is updated regularly, you should always consult the respective pricing pages for the latest information. Moreover, you should conduct your own performance and cost estimates using payloads that represent your workloads. Compression effectiveness varies significantly depending on the data type: payloads with low compression rates might not benefit from this technique.
Sample application
Follow the instructions in this GitHub repository to provision the sample in your AWS account. The project creates two Lambda functions to demonstrate receiving and returning compressed JSON using Function URLs and API Gateway.
The sample shows how to GET and POST JSON payloads using gzip compression to reduce the network footprint by over 80%.

Figure 11. A screenshot from Postman showing the original and compressed payload size
Conclusion
Data compression enables larger payload transfers and reduces network footprint. It can help to lower network latencies and optimize data transfer costs. When implementing compression within Lambda functions, it is important to consider its CPU-bound nature, which may increase function duration and costs. You should always evaluate the added compute cost against potential data transfer savings to make sure the technique benefits your use case.
Compression is most effective for handling large text-based payloads and when a slight increase in compute latency balanced by reduced network latency is acceptable.
To learn more about Serverless architectures and asynchronous Lambda invocation patterns, see Serverless Land.