AWS Database Blog
Scheduled scaling of Amazon Aurora Serverless with Amazon EventBridge Scheduler
Modern applications require relational databases that can handle variable workloads while maintaining performance and cost-effectiveness. While Amazon Aurora Serverless automatically scales based on metrics like CPU and memory usage, some applications need predictable capacity adjustments at specific times. For instance, daily reporting jobs at 9am may require increased capacity beforehand to ensure timely completion.
In this post, we demonstrate how you can implement scheduled scaling for Aurora Serverless using Amazon EventBridge Scheduler. By proactively adjusting minimum Aurora Capacity Units (ACUs), you can achieve faster scaling rates during peak periods while maintaining cost efficiency during low-demand times.
Use case overview
Some example use-cases for this pattern are:
- Daily usage where traffic spikes at a specific time of day (such as 9am).
- Special events where traffic spikes on a given day (for example a “flash sale” for a e-commerce platform).
- A system failure is identified in the application and additional workload is expected at the database.
- Specific application usage patterns where increased performance is expected.
An example usage pattern is shown in the graph that follows where there is a sharp increase in activity at 9am:

With traditional relational databases, this is solved by provisioning for peak. By provisioning for peak, the database will be over-provisioned for much of the day, leading to wasted resources. As shown in the following graph, all the shaded area is wasted compute resources.

Aurora Serverless solves this by dynamically scaling up and down compute resources in response to changing activity patterns. These scaling actions increase or decrease the available Aurora Serverless capacity units. During the initial ramp-up period, depending on how high the database needs to scale, it may take several minutes to reach the full compute capacity required to meet the spike in traffic. While the workload starts receiving additional resources immediately, these incremental capacity increases may not be sufficient to fully handle the increased demand until the required capacity is met.
While this ramp-up happens, there might be requests that time out, or generally a degraded quality of service.
Automatic scaling adjusts capacity dynamically based on fluctuating workloads throughout the day. Scheduled scaling, on the other hand, allows you to proactively set predetermined minimum and maximum capacity levels for anticipated peak usage periods. By adjusting the minimum capacity setting in advance, you can ensure your database has sufficient baseline capacity to handle expected workload increases. By combining these methods, you can optimize database performance and cost-efficiency. The following diagram shows an example where the utilization is much closer to the provisioned resource, therefore there is less wasted compute:
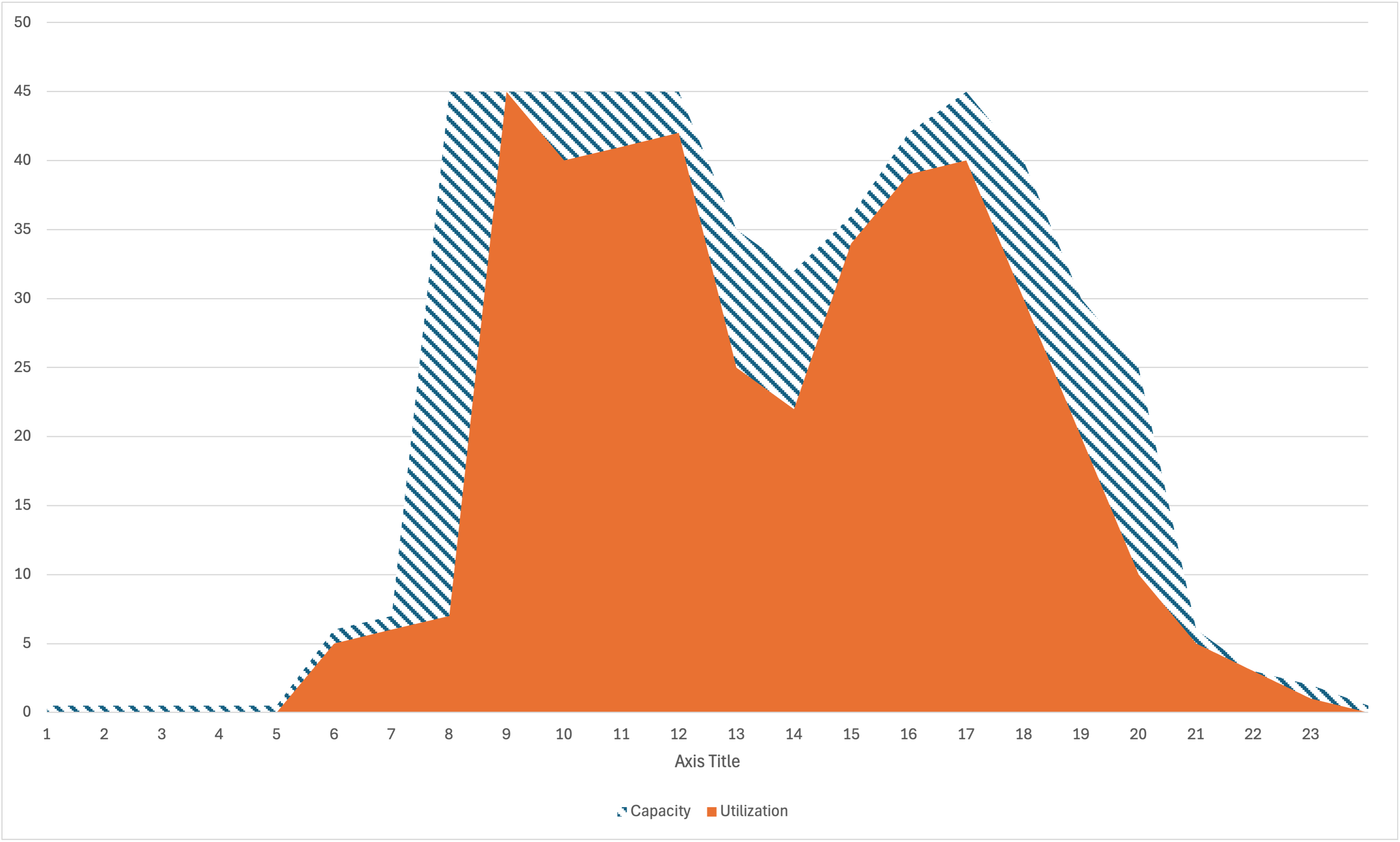
Changing the capacity configuration of Aurora Serverless is a non-disruptive operation. You can change this at any time and it doesn’t interrupt your existing workload or connections. This is unlike traditional database deployments where changing the capacity will trigger at the least a failover event to a standby or replica instance.
Solution overview
The solution uses a serverless, event-driven architecture to scale Aurora Serverless capacity at specific times. The following diagram illustrates the solution architecture.

The solution consists of the following key components:
- Aurora Serverless – Aurora Serverless automatically adjusts its capacity (Aurora capacity units (ACU)) between a configured minimum and maximum capacity range in response to changes in database load.
- EventBridge Scheduler – A recurring schedule (for example, a cron expression) triggers events at known intervals. For instance, an EventBridge schedule might run at 08:00 UTC every day to initiate a scale-up event. Another rule might run later in the day to scale capacity back down during off-peak hours.
- IAM role – The EventBridge schedule assumes an AWS Identity and Access Management (IAM) role. The IAM role is scoped to provide access to the ModifyDBCluster The schedule interacts with Aurora using a universal target using the Amazon Relational Database Service (Amazon RDS) API directly. It identifies the target Aurora cluster and calls the
ModifyDBClusterAPI operation, passing in a payload specifying the desired minimum and maximum capacity units.
In the following sections, we walk through the steps to implement this scheduled scaling solution.
Prerequisites
You should have the following prerequisites:
- An Aurora cluster with at least one Amazon Serverless instance – The solution requires an existing Aurora Serverless (MySQL or PostgreSQL-compatible) instance. You must know the cluster identifier, the desired minimum and maximum capacity units, and have permissions to modify the cluster.
- The AWS CDK – The sample is deployed using the AWS Cloud Development Kit (AWS CDK). This post references code and configuration from the following GitHub repository.
Step 1: Clone the repository
Start by cloning the repository and changing to the sample directory:
This AWS CDK app defines the infrastructure components, including the EventBridge schedule and necessary IAM permissions.
The cdk.context.json file contains the schedule configuration. This can be configured with either a scale-up schedule, a scale-down schedule, or both using a cron expression. Additionally, the dbClusterIds specifies which clusters to target (this corresponds to the DBClusterIdentifier parameter from the cluster).
Step 2: Define the scaling schedule
It is important to understand the upper limits for your database. If you set the maximum capacity to a value too low, you risk disrupting your service. For example, if your database is currently using 128 ACU and your scheduled scaling action drops the max ACU to 64, this action will take precedence. This means that the workload can be negatively impacted if you don’t time your scaling actions appropriately.
To determine this, you can run your database for a period without the scheduled scaling actions. After a few days of activity, review the ServerlessDatabaseCapacity metric from Amazon CloudWatch. This metric will allow you to determine where you can make your planned scheduled scaling actions to avoid disruption to your service.
In the cdk.context.json file, define a cron expression that indicates when scaling should occur. For example, to scale up at 08:00 UTC every day and scale down at 18:00 UTC every day, use the following code (note the desired capacity unit is ACU):
If you wanted to only schedule the scale up action and let Aurora Serverless manage the scale down on its own, you can omit the scale down schedule (or vice versa):
If you wanted to run the solution against multiple clusters, you can provide additional cluster Ids:
Step 3: Deploy the solution
Use the AWS CDK CLI to build and deploy the solution:
The AWS CDK app creates the following:
- EventBridge schedules that trigger the Amazon RDS API at the specified times
- IAM roles and policies that allow EventBridge to call the Amazon RDS APIs
Step 4: Test the scheduled scaling
After deployment, you can verify the updated Aurora capacity as follows:
Look for the minimum and maximum capacity in the output to confirm the scaling action succeeded:
Alternatively, you can use the Amazon RDS console to view the cluster’s status and capacity changes.
Operational considerations
There are a few operational considerations you can follow, to manage the costs, performance, observability, and security of the scheduled scaling solution for Aurora Serverless v2.
- Cost management – Scheduled scaling may increase Aurora capacity during certain times, potentially increasing costs if capacity is maintained at a higher level for an extended period. The trade-off is improved performance during known peaks. Continually review workloads, scaling windows, and scaling levels to make sure that the cost-to-performance ratio remains optimized.
- Observability and logging – Implement robust logging and create CloudWatch alarms on error metrics for the schedule. If a scaling event fails, operators should be notified promptly. Additionally, logs can help refine scaling decisions over time. If, for instance, scaling up 10 minutes before a large job proves insufficient, adjust the timing or capacity accordingly.
- Security and governance – Make sure that the roles and policies granting permissions to EventBridge follow least-privilege principles. The EventBridge execution role should only allow access to the specified Aurora cluster. It is recommended to store the primary user for the Aurora cluster in AWS Secrets Manager when using this solution. Because the modify DB cluster API call allows changing the primary password, to avoid abuse, this should be stored externally in Secrets Manager with an implicit deny in the execution IAM policy.
Cleanup
To delete the solution and remove all resources when you are done, use the CDK destroy command:
Conclusion
Balancing cost and performance are key challenges in designing and operating databases at scale. Aurora Serverless provides an ideal starting point by adjusting capacity based on load. However, predictable demand patterns often warrant more proactive scaling to maintain optimal performance at specific times. By integrating EventBridge, you can implement scheduled scaling for Aurora Serverless, better preparing your databases for known workload spikes and driving more consistent end-user experiences.
In this post, we showed you how to build a reliable and extensible mechanism for scheduled scaling of Aurora Serverless. By using infrastructure as code and serverless AWS services, you can adapt and extend the solution to meet your operational requirements. For more database samples and patterns, check out the following Data-for-saas-patterns repository on GitHub.
About the Author
 Josh Hart is a Principal Solutions Architect at AWS. He works with ISV customers in the UK to help them build and modernize their SaaS applications on AWS.
Josh Hart is a Principal Solutions Architect at AWS. He works with ISV customers in the UK to help them build and modernize their SaaS applications on AWS.