AWS News Blog
Amazon Aurora Update – Create Cluster from MySQL Backup
After potential AWS customers see the benefits of moving to the cloud, they often ask about the best way to migrate their applications and their data, including large amounts of structured information stored in relational databases.
Today we are launching an important new feature for Amazon Aurora. If you are already making use of MySQL, either on-premises or on an Amazon EC2 instance, you can now create a snapshot backup of your existing database, upload it to Amazon S3, and use it to create an Amazon Aurora cluster. In conjunction with Amazon Aurora’s existing ability to replicate data from an existing MySQL database, you can easily migrate from MySQL to Amazon Aurora while keeping your application up and running.
This feature can be used to easily and efficiently migrate large (2 TB and more) MySQL databases to Amazon Aurora with minimal performance impact on the source database. Our testing has shown that this process can be up to 20 times faster than using the traditional mysqldump utility. The database can contain both InnoDB and MyISAM tables; however, any MyISAM tables will be converted to InnoDB as part of the cluster creation process.
Here’s an outline of the migration process:
- Source Database Preparation – Enable binary logging in the source MySQL database and ensure that the logs will be retained for the duration of the migration.
- Source Database Backup – Use Percona’s Xtrabackup tool to create a “hot” backup of the source database. This tool does not lock database tables or rows, does not block transactions, and produces compressed backups. You can direct the tool to create one backup file or multiple smaller files; Amazon Aurora can accommodate either option.
- S3 Upload – Upload the backup to S3. For backups of 5 TB or less, a direct upload via the AWS Management Console or the AWS Command Line Interface (AWS CLI) is generally sufficient. For larger backups, consider using AWS Snowball.
- IAM Role – Create an IAM role that allows Amazon Relational Database Service (Amazon RDS) to access the uploaded backup and the bucket it resides within. The role must allow RDS to perform the
ListBucketandGetBucketLocationoperations on the bucket and theGetObjectoperation on the backup (you can find a sample policy in the documentation). - Create Cluster – Create a new Amazon Aurora cluster from the uploaded backup. Click on Restore Aurora DB Cluster from S3 in the RDS Console, enter the version number of the source database, point to the S3 bucket and choose the IAM role, then click on Next Step. Proceed through the remainder of the cluster creation pages (Specify DB Details and Configure Advanced Settings) in the usual way:
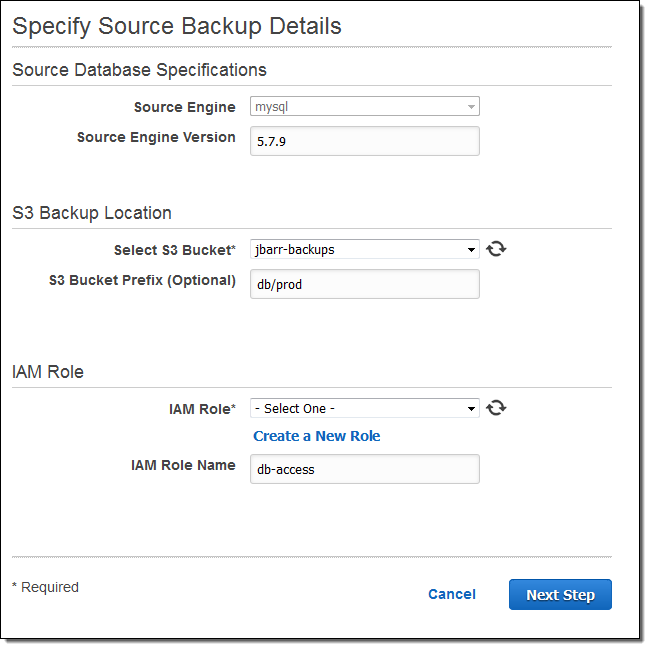
Amazon Aurora will process the backup files in alphabetical order.
- Migrate MySQL Schema – Migrate (as appropriate) the users, permissions, and configuration settings in the MySQL INFORMATION_SCHEMA.
- Migrate Related Items – Migrate the triggers, functions, and stored procedures from the source database to the new Amazon Aurora cluster.
- Initiate Replication – Begin replication from the source database to the new Amazon Aurora cluster and wait for the cluster to catch up.
- Switch to Cluster – Point all client applications at the Amazon Aurora cluster.
- Terminate Replication – End replication to the Amazon Aurora cluster.
Given the mission-critical nature of a production-level relational database, a dry run is always a good idea!
Available Now
This feature is available now and you can start using it today in all public AWS regions with the exception of Asia Pacific (Mumbai). To learn more, read Migrating Data from an External MySQL Database to an Amazon Aurora DB Cluster in the Amazon Aurora User Guide.
— Jeff;